
音声入力をデフォルトに寄せる試行(ここ1ヶ月の所感)
ここ1ヶ月ほど、仕事の「入力」をできるだけ音声に寄せる試行をしている。
メモ、思考整理、AIとの対話、企画の叩き台、文章の下書き、作業の段取りづくり……できるところはなるべく声で進める、という方針。
先に結論を書くと、音声→テキストが急に賢くなったからではない。音声入力自体は、僕の感覚では以前から十分実用域だった。
運用を変える気になった主因は、最近のAIが「多少荒い入力」を受けても、こちらの意図を再構成して、整形し、構造化し、必要なら次のアクションにまで落としてくれる局面が増えたことにある。
要するに、入力に求められる“完成度”が変わった。
入力の役割の変化
従来は、入力(=文章化)の時点で人間が構造を作り切る必要があった。
論旨を立て、順序を整え、誤りを潰し、伝わる形にまで整えてから外に出す。キーボードは、その構造化を人間が担うための道具だった。
いまは、入力は素材でよい。
多少の誤変換や言い淀み、話が前後しても、AIが意図を拾って、文章にし、箇条書きにし、論点を分け、タスクに分解し、場合によっては「次に何をするか」まで提案してくる。
人間は、最終的な判断とレビュー、そして「何を/なぜ」を引き受ければよい。
入力を
- 「正確に書く(=構造を自分で作る)」
- 「まず吐き出す(=あとでAIが整える)」
に寄せられる。
この“要求水準の変化”が、僕にとっては転換点だった。
いまの運用(ざっくり)
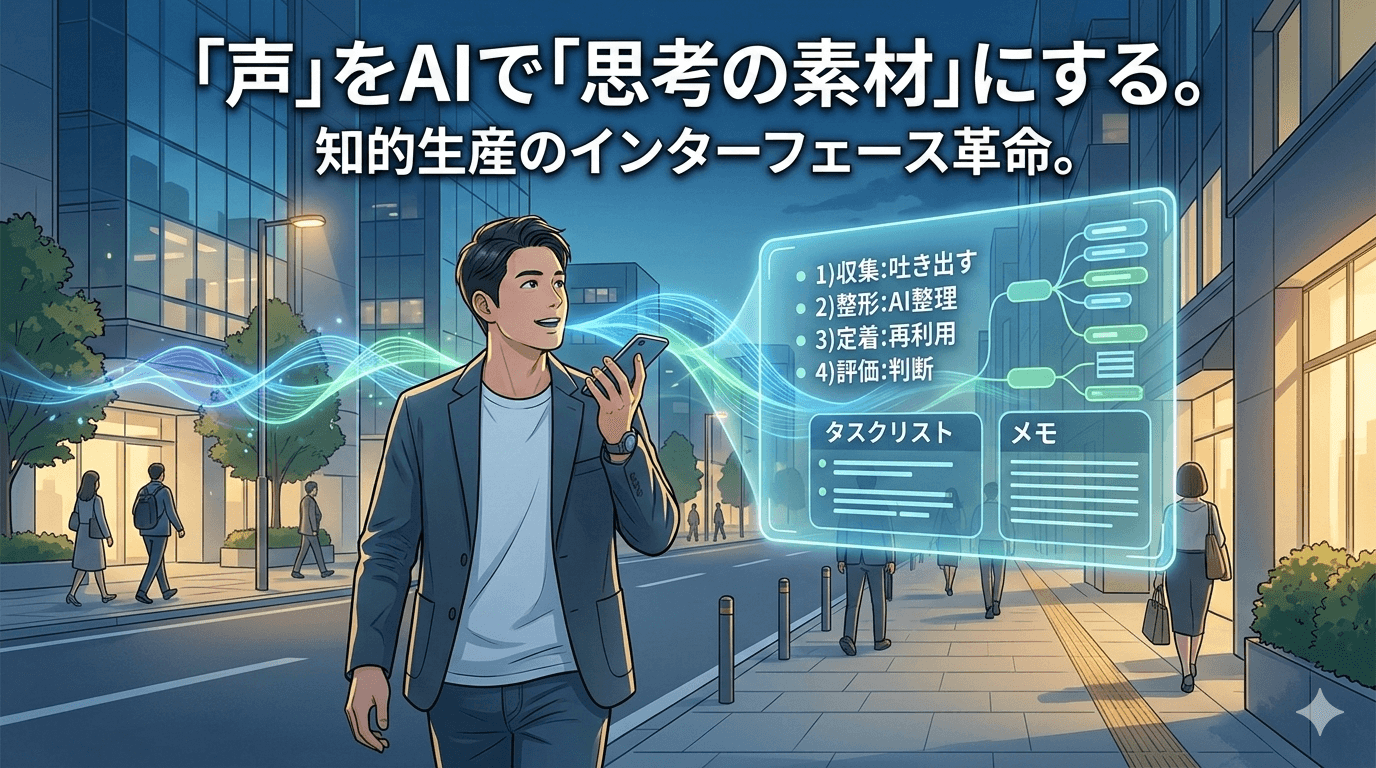
僕の中では、だいたい次の流れで回している。
- 収集:思いついたことをまず吐き出す(音声で良い。粗くて良い)
- 整形:AIに整理させる(論点、前提、選択肢、リスク、次アクション)
- 定着:後で再利用できる形に置く(メモ、タスクリスト、文章の骨子、設計の要点など)
- 評価:人間がレビューして、進める/捨てる/保留するを決める
この“整形→定着”が現実的になったことで、入力が「丁寧に作る工程」から「素材を供給する工程」に寄ってきた感じがある。
個人開発は一事例(抽象度が高い領域ほど効く)
この運用は、個人開発だと分かりやすく効く(コンテキストが途切れやすいから)が、それだけの話ではない。
例えば、
- 趣味で事業計画みたいなものを雑に作って、AIに論点整理させる
- 記事の構成案を声で投げて、章立てと論旨を作らせる
- 音楽の方向性(雰囲気、構成、歌詞のテーマ)を吐き出して、候補を並べさせる
- 仕事の打ち合わせ後に要点と次の打ち手をまとめさせる
- 「今の自分は何に疲れているか」を言語化して、行動案に落とす
こういう、抽象度の高い材料を扱うほど、AIが“整形して使える形にする”価値が出てくる。
作れるかどうか、よりも、何を作るか/なぜ作るか、の側に重心が移っていく時代感とも相性がいいと思っている。
音声入力の利得(速度ではなく、身体と注意)
音声入力の利得は、速度というより「身体性」と「注意の配分」にある。
タイピングは、思っている以上に
- 姿勢(机に向かって固定される)
- 視線(入力結果を追い続ける)
- 注意(指先と画面に引っ張られる)
を拘束する。
音声入力に寄せると、この拘束が一段ゆるむ。
歩きながらでも進むし、視線も自由になる。今この文章も、部屋の中を歩きながら入力している。
思考対象から意識を逸らしにくい、という意味で、思考の連続性が保たれやすい。これは積み上がると差になる。
僕がやりたいのは、たくさん働くというより、
「集中力や体力を無駄に消耗しない形で、試行回数を増やす」
という方向の最適化に近い。入力の摩擦が減ると、思考の実験回数が増える。これは単純だが強い。
制約(ここはまだ現実の壁)
もちろん制約もある。
- 公共空間:電車は無理。コワーキングやカフェも、気まずさとプライバシーの問題で現状はまだ難しい
- 物理環境:外ではノイズを拾い、品質が落ちる
ここは音声認識の問題というより、社会環境とデバイスの問題が大きい。
指向性マイク等を買うかは検討中だが、音声×AIが主戦場になるなら、それを前提にした機材やデバイスが出てくるのも自然なので、いまは少し様子見している部分もある(とはいえ、しびれを切らして買う可能性は普通にある)。
1〜2年の見立て(強さより、接点の設計)
音声認識やノイズ耐性の改善は当然進むとして、僕がより重要だと思っているのは、エージェントの“強さ”そのものより
「人間とエージェントの接点(UI/UX)が整備されること」
だ。
いまは極端になりやすい。
人が細かく操作してAIは補助、か、エージェントに丸投げして人は眺める、か。
現実に欲しいのは中間で、
- AIが何をしようとしているかが分かる
- こちらの意図(思想)を注入しながら進められる
- 判断の根拠と進捗が見える
という「協働の設計」だと思う。
そこが整えば、
「口で指示 → AIが整形/構造化/記録/反映 → 人間は要所だけ判断」
が“手に馴染む標準”になる。
さらにもう少し先の大本命としては、視界側のインターフェース(いわゆるAIグラス的なもの)もある。
表示の品質、重量、情報提示の設計、音声入出力の統合が現実的な水準に揃ってくると、ディスプレイとキーボードに身体が縛られる時間は一段減るはずだ。
最後に
音声入力やエージェントが進化すると、「家でひとりでコツコツ」が有利になる面はあると思う。
ただ、ソーシャルな交流が不要になるかというと、むしろ逆で、作業を短時間で濃く片付けられるようになる分、
- 人と会って話す
- 場を共有する
- そこから発想を得る
といった時間の価値が上がる気もしている。
作業は圧縮して、交流は大事にする。メリハリが取りやすくなる、という見立て。
という感じで、ここ1ヶ月ほど、音声入力をデフォルトに寄せる実験をしている。
おすすめの運用(場所の工夫、機材、アプリ、やり方)があれば、ぜひ教えてほしい。